SPX from 2000 + residual with eps model price + CLI 1 month delta.
kikan <- "2000-01-01::"
func <- function(x){
if(is.na(x)){return(NA)}
if(x > 0.1){return("a")}
if(x > 0){return("b")}
if(x > -0.1){return("c")}
if(x < -0.1){return("d")}
}
delta <- append(as.vector(diff(cli_xts$oecd)[kikan]),rep(NA,length(index(tmp.predict)) - length(diff(cli_xts$oecd)[kikan])))
# [kikan]
df <- data.frame(i=as.vector(tmp.predict[kikan][,4]),
g=as.vector(tmp.predict[kikan][,6]),
e=as.vector(tmp.predict[kikan][,7]),
r=as.vector((tmp.predict[kikan][,4]/tmp.predict[kikan][,7])-1)*5000,
# c=as.vector(apply(diff(cli_xts$oecd)[kikan],1,func)),
c=as.vector(apply(matrix(delta,ncol=1),1,func)),
t=as.Date(index(tmp.predict[kikan])))
colnames(df)[1] <- 'i'
colnames(df)[2] <- 'g'
colnames(df)[3] <- 'e'
colnames(df)[4] <- 'r'
colnames(df)[5] <- 'clidelta'
p <- ggplot(df,aes(x=t))
#
# need to investigate mapping= designator. somehow it's necessary to overlay y-axis coordinated graph.
#
p <- p + geom_point(mapping=aes(y=i,colour=clidelta),stat="identity", position="identity",size=0.8)
p <- p + geom_path(aes(y=i),stat="identity", position="identity",colour="black",linetype="dotted")
p <- p + scale_x_date(date_breaks = "2 year", date_labels = "%Y")
# same as above about mapping=
p <- p + geom_path(aes(y=g),colour='red')
p <- p + geom_path(aes(y=e),colour='blue')
p <- p+annotate("text",label=as.character("10%"),x=as.Date("2020-01-01"), y=550,colour='black')
p <- p + geom_hline(yintercept = 250,size=0.5,linetype=1,colour="white",alpha=1)
p <- p+annotate("text",label=as.character("5%"),x=as.Date("2020-01-01"), y=300,colour='black')
p <- p + geom_hline(yintercept = -250,size=0.5,linetype=1,colour="white",alpha=1)
p <- p+annotate("text",label=as.character("-5%"),x=as.Date("2020-01-01"), y=-200,colour='black')
p <- p + geom_bar(aes(y=r,fill=clidelta),stat = "identity",colour="black") # need identity to draw value itself.
p <- p + theme(axis.title.x=element_blank(),axis.title.y=element_blank())
p <- p + labs(title = "SPX + Theory + Residual% + CLI 1 month Delta",fill="CLI Delta",colour = "CLI Delta")
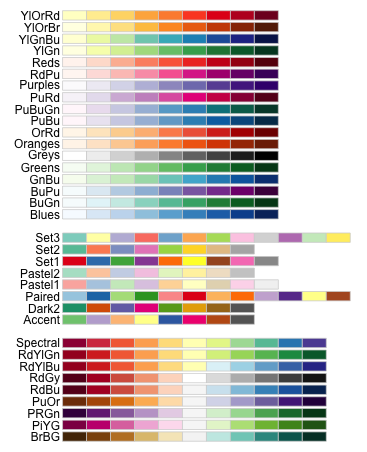
p <- p +scale_color_brewer(palette="Spectral",na.value = "black",name = "CLI Delta", labels = c("High","mid High","mid Low","Low","NA"))
p <- p +scale_fill_brewer(palette="Spectral",na.value = "black",name = "CLI Delta", labels = c("High","mid High","mid Low","Low","NA"))
p <- p+theme( rect = element_rect(fill = "grey88",
colour = "black",
size = 0,
linetype = 1),
panel.background = element_rect(fill = "grey88",
colour = "lightblue"),
axis.title.x=element_blank(),
axis.title.y=element_blank()
)
# p <- p + scale_fill_discrete(name="Experimental\nCondition")
# p <- p +scale_colour_discrete(name ="CLI Delta") + scale_shape_discrete(name ="CLI Delta")
plot(p)
# remove unnecessary function.
remove(func)
remove(df)


















{kind=link}